
یادگیری تقویتی چیست و چرا مهم است؟
یادگیری تقویتی (Reinforcement Learning یا RL) یکی از شاخههای مهم یادگیری ماشین است که به جای استفاده از دادههای برچسبدار، به عامل (agent) اجازه میدهد از طریق تعامل با محیط، بهترین تصمیم را بیاموزد و پاداش تجمعی را بیشینه کند. synopsys.com+2Wikipedia+2
در این روش، عامل با انجام عمل در محیط و دریافت بازخورد (پاداش یا تنبیه)، رفتار خود را اصلاح میکند تا در درازمدت عملکرد بهتری داشته باشد.
به عبارت دیگر، یادگیری تقویتی به ماشینها کمک میکند تا از آزمونوخطا یاد بگیرند، همانطور که انسانها در محیط پیرامون خود تجربه کسب میکنند.
مؤلفهها و مفاهیم کلیدی در یادگیری تقویتی
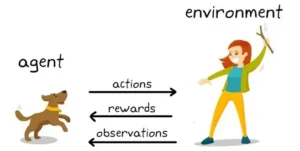
محیط (Environment) و عامل (Agent)
عامل، موجودیتی است که در محیط قرار دارد، وضعیت را میبیند، عمل انتخاب میکند و سپس محیط پاسخ میدهد (وضعیت جدید + پاداش).
حالت (State)، عمل (Action) و پاداش (Reward)
-
حالت (State): نمایانگر شرایط فعلی محیط است.
-
عمل (Action): تصمیم یا کاری است که عامل انجام میدهد.
-
پاداش (Reward): بازخورد فوری از محیط که نشان میدهد عمل انجامشده چقدر مفید بوده است.
سیاست (Policy)، تابع ارزش (Value Function) و فرآیند تصمیمگیری
-
سیاست: رابطهای بین حالتها و اعمال؛ عامل با استفاده از سیاست تصمیم میگیرد چه کاری انجام دهد. GeeksforGeeks
-
تابع ارزش: تخمینی از جدایی بلندمدت پاداشهایی که از حالت یا حالت–عمل خاص میتوان بهدست آورد.
مدلدار (Model-based) vs «بدون مدل» (Model-free)
یادگیری تقویتی میتواند شامل الگوریتمهایی باشد که محیط را مدلسازی میکنند یا نه. الگوریتمهای بدون مدل (model-free) بهویژه در محیطهای بزرگ و پیچیده کاربرد دارند.
مثال کاربردی: یادگیری تقویتی در بازی
فرض کنید عاملی داریم که در بازی «مار و پله» (یا سادهتر، یک بازی مسیر یابی) فعالیت میکند.
-
عامل در هر وضعیت (مثلاً در سلول ۵ از مسیر) تصمیم میگیرد به چپ برود یا راست.
-
اگر به پایان مسیر برسد، پاداش مثبت میگیرد؛ اگر به مانع بخورد، پاداش منفی.
-
عامل با امتحان کردن مسیرهای مختلف (اکتشاف) و استفاده از مسیرهای موفق (بهرهبرداری) یاد میگیرد سیاست بهینه را پیدا کند: کدام حرکت در هر وضعیت بیشترین پاداش در بلندمدت میدهد.
این فرآیند دقیقاً مطابق با چارچوب یادگیری تقویتی است که در مقالات ذکر شده است: عامل–محیط–اقدام–پاداش.
در دنیای واقعی، مثالی معروف است: الگوریتمهایی که بازیهای آتاری، بازی Go یا حتی رانندگی خودکار را با استفاده از RL آموزش دادهاند.
چرا یادگیری تقویتی مهم است؟
-
توانایی تصمیمگیری در محیطهای پویا و ناشناخته: RL میتواند بدون دادههای برچسبدار، یاد بگیرد که چه باید بکند.
-
بهینهسازی پاداش تجمعی: برخلاف یادگیری نظارتشده که فقط تلاش در کمینهکردن خطا دارد، RL به دنبال بیشینهکردن پاداش طولانیمدت است.
-
کاربرد گسترده در رباتیک، بازیها، خودرانها، بهینهسازی فرآیندها و … .
چالشها و نکات فنی
-
طراحی تابع پاداش: اگر پاداش بهدرستی تعریف نشود، عامل ممکن است راهکارهایی یاد بگیرد که نامطلوب هستند.
-
تعادل بین اکتشاف (Exploration) و بهرهبرداری (Exploitation) و همچنین ابعاد بزرگ فضای حالت و عمل.
-
محیطهای واقعی ممکن است «ناظرناپذیر» (Partially Observable) باشند یا مدلسازی سخت باشد؛ بنابراین استفاده از RL در جهان واقعی نیازمند تلاش و داده زیاد است.
-
هزینه محاسباتی و زمان آموزش بالا، بهویژه در الگوریتمهای عمیق تقویتی (Deep RL).
آینده یادگیری تقویتی و کاربرد در ایران
یادگیری تقویتی با رشد هوش مصنوعی و افزایش قدرت محاسبات، بیش از پیش در ایران نیز کاربرد پیدا خواهد کرد — بهویژه در زمینههای:
-
رباتیک صنعتی و خودکارسازی خطوط تولید
-
بهینهسازی مصرف انرژی در ساختمانها و شبکههای هوشمند
-
بازیهای رایانهای آموزشی و واقعیت مجازی
-
کاربردهای مالی و الگوریتمی در بازارها
با بهکارگیری آن، شرکتها و سازمانها میتوانند سیستمهای تصمیمگیر خودیادگیر داشته باشند که به مرور عملکردشان بهتر میشود.
جمعبندی
یادگیری تقویتی (RL) یکی از پیشرفتهترین روشهای یادگیری ماشین برای حل مسائلی است که طراحی مستقیم سیاست برای آنها مشکل است. با درک صحیح مفاهیم آن — عامل، محیط، پاداش، سیاست — میتوان پروژههای کاربردی موفقی راهاندازی کرد. اگر مایل باشید، میتوانم مقالهای برای استفاده در سایت فارسی آماده کنم همراه با مثال کد پایتون، منابع برای مطالعه بیشتر و لینک به ابزارهای رایگان.
سوالات متداول FAQ
1. یادگیری تقویتی چیست؟
یادگیری تقویتی یا Reinforcement Learning شاخهای از یادگیری ماشین است که عاملها با تعامل با محیط و دریافت پاداش یا تنبیه، تصمیمگیری بهینه را میآموزند.
2. تفاوت یادگیری تقویتی با یادگیری نظارتشده چیست؟
در یادگیری نظارتشده دادهها برچسبدار هستند، اما در یادگیری تقویتی عامل باید از تجربه و بازخورد محیط یاد بگیرد، نه از دادههای از پیش آماده.
3. یادگیری تقویتی در چه حوزههایی استفاده میشود؟
از رباتیک و خودروهای خودران گرفته تا بازیها، مالی، آموزش، و بهینهسازی فرایندهای صنعتی—all از RL استفاده میکنند.
4. الگوریتمهای معروف در یادگیری تقویتی کداماند؟
از جمله الگوریتمهای معروف میتوان به Q-Learning، Deep Q-Network (DQN)، Policy Gradient، و PPO (Proximal Policy Optimization) اشاره کرد.
5. آیا یادگیری تقویتی در ایران کاربرد دارد؟
بله، در صنایع تولیدی، کشاورزی هوشمند، و حوزههایی مانند کنترل ربات، پیشبینی بازار و مدیریت انرژی در حال رشد است.
6. چالشهای یادگیری تقویتی چیست؟
از جمله چالشها میتوان به نیاز به داده زیاد، طراحی تابع پاداش مناسب، هزینه محاسباتی بالا و پیچیدگی در مدلسازی محیط اشاره کرد.





دیدگاه ها بسته هستند